Experiments
V23: World-Model Gradient
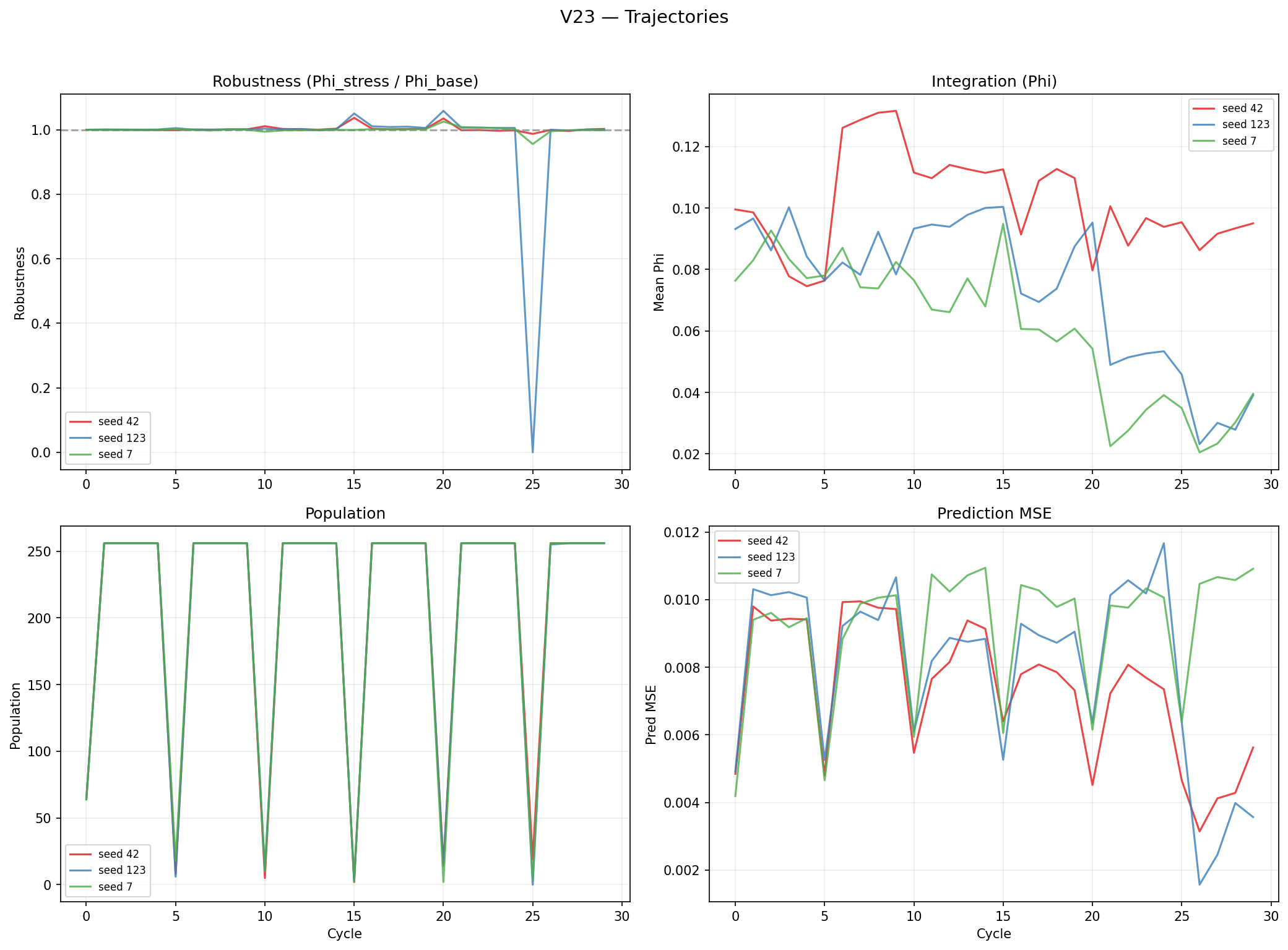
V23: World-Model Gradient
Period: 2026-02-19. Substrate: + 3-target prediction head (energy, resources, neighbors).
Hypothesis: Multi-dimensional prediction, with targets from different information sources, forces integrated representations.
| Metric | Seed 42 | Seed 123 | Seed 7 | Mean |
|---|---|---|---|---|
| Mean | 0.102 | 0.074 | 0.061 | 0.079 |
| Col cosine | 0.215 | -0.201 | 0.084 | 0.033 |
| Eff rank | 2.89 | 2.89 | 2.80 | 2.86 |
Specialization ≠ integration. Weight columns specialize beautifully (cosine ~ 0, near-orthogonal). But specialization means MORE partitionable, not less. decreases (0.079 vs 's 0.097). Factored representations can be cleanly separated.
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.
- — Multi-target prediction head
- — Evolution loop
- — GPU runner